If you have ever attended a talk in which the presenter shows a line tracing the popularity of a word or phrase over the decades or centuries, then you likely have witnessed the fruits of computational text analysis, or text mining. More and more scholars and scientists are turning to the “Google Ngram” viewer to help their audiences clearly visualize changing trends in vocabulary and written discourse. Not all of them know, however, how it is that Google can instantly produce such sleek visual representations from such a massive corpus of texts.
Computational text analysis occupies a prominent place among the assemblage of practices, methods, and questions collectively called the “Digital Humanities.” Practitioners of text mining are engaging in the same pursuit that has defined most humanistic scholarship since the Renaissance: the articulation of meaning (or meanings) embedded in written text.
Past centuries have occasionally seen new technologies designed to help scholars to read more texts and trace new continuities or ruptures among them. Scholars in the sixteenth century witnessed the invention of the “Bookwheel,” a clunky contraption that enabled them to cycle more quickly from text to text with the help of gears and levers. But nothing from the past can remotely compare to the powerful tools available in the 21st century, when scholars and scientists can turn to computer programs to help them examine not dozens but hundreds—or thousands or millions—of texts at once.
While some praise the advent of computational text analysis as a revolutionary method for the analysis of texts at an order of magnitude never before possible, others criticize these “distant reading” methods as a challenge to the tradition of “close reading” that is considered central to the contemporary literary humanities and social sciences. Misconceptions about the programs, texts, and methods central to computational text analysis abound on both sides of the debate. Before engaging in computer-assisted textual research—or jumping into the debate about this method—it is important to understand the basics.
1. Texts and Sources
Whether they realize it or not, nearly all scholars and scientists working today, even ardent traditionalists, employ complex algorithms to consult digital texts. After all, every Google search for an author or article relies on search functions that read through a massive corpus of digital texts to sort and summon the results to best fit the entered parameters. Computational text analysis relies on the same fundamental components: digital texts, computer programs, and researchers who know how to use them, even if they don’t necessarily understand how they work.
Most scholars and scientists have become perfectly comfortable using digital texts for readings and research. Scholars using computers to read and analyze books tpically begin by collecting their sources, a corpus of digital texts. Someone wanting to analyze a handful of classics can simply hit the download button a few times to access plain text files from online repositories like Project Gutenberg. For researchers working on larger-scale efforts, such as the Mining the Dispatch project, an analysis based on 112,000 articles from a Civil War-era newspaper, acquiring all the texts requires some expertise in computer programming; programs can help "scrape” data from thousands of files contained in online databases.
While this first step may seem mundane, it immediately introduces key assumptions that could shape the eventual research findings. For example, computational analysis of digital texts typically forces scholars and scientists to rely on archives of newspapers and libraries that have already been digitized. That reliance can privilege prominent newspapers and affluent libraries. Ian Milligan, a historian at the University of Waterloo, confirmed these concerns when he found a considerable rise in the number of Canadian history dissertations that consulted only the two national newspapers that had digitized their archives, at the expense of smaller, regional publications.
2. The “Bag of Words”
Though not common to all methods of computational text analysis, the “bag of words” assumption underlies many of the most prominent approaches. This unflattering description captures how researchers often program computers to read books as a collection of words separated by spaces, stripped of any logical order or meaning.
Such a banal way of “reading” seems at first glance to confirm all the direst warnings of the critics of the digital humanities, but the “bag of words” permits extremely powerful methods of analyzing large collections. By approaching texts as words that can be counted, computers can be programmed to quantify the lexicons that authors deploy in their writings and compare them at a scale several orders of magnitude beyond what humans could accomplish in a lifetime.
Even if “bags of words” fail to capture what is most sophisticated or sublime in literature, they can provide models for how we describe language, whether positive or negative, modern or archaic, and so on. For example, the political scientists Justin Grimmer and Brandon Stewart show how a researcher studying thousands of congressional floor speeches on a particular issue might make lists of words common to the pro and con positions, and then classify speeches based on the prevalence of those words, thereby saving him or her from the tedious task of reading speeches and identifying the obvious. This quantitative approach to “sentiment analysis” represents just one example of how “bags of words” can generate interesting insights from texts.
3. “Supervised” Vs. “Unsupervised” Methods
Not every “bag of words” method confines the researcher to simple, pre-determined categories. A political scientist studying floor speeches might be able to determine not only a particular politician’s position on a policy with these methods, but also the argument provided in favor or against. The first question demands an answer from “supervised” classification methods, while the second more likely requires an “unsupervised approach.”
In the simplest terms, supervised methods allow the researcher to construct a classification scheme first, and then categorize the texts within the scheme based on the words they contain. Unsupervised methods read all the texts first and then suggest which classification scheme(s) might apply.
An important but sometimes overlooked difference divides these methods and the questions they can answer. In his critique of computational text analysis, the literary critic Stanley Fish offers a one-sided characterization of these methods, claiming that “in the digital humanities...first you run the numbers, and then you see if they prompt an interpretive hypothesis.” That description applies only to the “unsupervised” methods, however, and misses the mark on supervised approaches like sentiment analysis.
A method called “Topic Modelling” stands at the forefront of unsupervised classification methods. Through special computer programs like the open-source MALLET, researchers can produce “topics” composed of those words that most frequently occur together in the same texts. In his Mining the Dispatch project, the historian Robert Nelson employed a topic-modelling method to determine the number of runaway-slave advertisements published in the Richmond Dispatch throughout the Civil War. The program read over one hundred thousand articles and generated several topics so that Nelson could identify one topic that corresponded to runaway-slave advertisements, based on the kinds of words frequently included in that genre. The program then assigned all articles a value that represented the prevalence of the “runaway-slave advertisement words” in each, allowing Nelson to count all articles that closely fit that designation.
Although Nelson knew what he was looking for, the topic-modelling method he employed could have uncovered surprising similarities in the words used to describe runaway-slaves and Union soldiers, for instance. Topic-modelling produced a characterization of the articles that was unmarred by the historian’s presuppositions, but it still left him in the position to identify—based on his own expectations—which topic described what he was looking for. All methods, no matter how “unsupervised,” ultimately rely on the scholar’s supervision.
4. Beyond the “Bag of Words”
Although the “bag of words” model is more powerful than it sounds, it is not the only way a computer can read a text. Computer and data scientists and mathematicians have developed programs that provide computers with the capacity to read beyond the lexicon and capture the syntactic relations that bind words to produce meaning.
Programs such as the Stanford Parser, which “parses” sentences into their grammatical parts, has introduced the fruits of the rapidly developing field of “natural language processing” (NLP) to computational text analysis. Researchers working on these programs hope to more accurately simulate human ways of reading that take them beyond the “bag of words.” With these methods, the computer might recognize that “to be or not to be” is a question, and not a rather repetitious assortment of short words.
Scholars and scientists have begun to explore how natural language processing might answer more complex research questions. Dr. David Bamman, a professor at UC Berkeley’s School of Information, and his colleague Dr. Noah Smith of the University of Washington, recently demonstrated how programs that can computationally parse political statements from online comment sections can allow researchers to isolate claims like “Obama is a socialist” or “global warming is a threat,” and then determine how their partisan affiliations differ from “Obama is the president” or “global warming is a hoax.”
Questions like Bamman and Smith’s cannot be answered with a “bag of words” approach. A commenter might post that “global warming is a hoax, but Iraq is a threat,” and another might respond that “the Iraq War is a hoax, global warming is the threat.” Both use almost the exact same words, but each carries radically different political implications. Only with programs that can identify what the users describe as threats and hoaxes can researchers judge the political meaning of each.
5. Resources at UC Berkeley
Through all the theoretical discussion that computational text analysis has generated in journals, conferences, and other forums, it is sometimes easy to miss the real-life scholars, scientists, and groups who rely on these methods for research on a regular basis. Researchers at any point in their careers can learn the programs that make this work possible, and at an institution like UC Berkeley, they need not rely on digital communities to guide them.
For example, anyone interested in topic-modelling an extensive collection of poems or analyzing the political implications of thousands of comments can begin by learning some basics behind one of the primary computer languages for computational text analysis projects, R and Python. The D-Lab at UC Berkeley offers free workshops and classes, such as “R for Data Science” and “Text Analysis,” designed to introduce newcomers to the methods needed to begin their own projects.
Computational text analysis is not as easy as learning how to write some computer code, which is why it can help to turn to communities on campus like the Computational Text Analysis Working Group, Digital Humanities Working Group, and the Literature and Digital Humanities Working Group, which welcome participants for presentations on ongoing computational text analysis projects and discussions of the methodologies and implications of their approaches.
Whether one considers computational text analysis to represent the cutting edge of humanities and social science research, a potential threat to the practices that make such scholarship unique, or some combination of both, there is no shortage of venues for discussion with colleagues on campus. Regardless of your familiarity with computational text analysis today, UC Berkeley offers an abundance of opportunities to learn more.
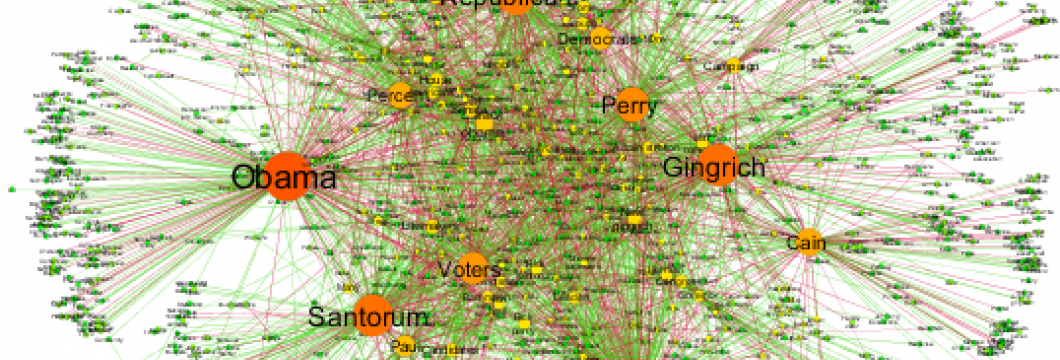
Photo Credit: Thinkbig-project. Narrative Network of US Election 2012 - Nodes indicate noun phrases, links go from subject to object, color expresses relation of support or opposition. Appeared in: "Automated analysis of the US presidential elections using Big Data and network analysis; S Sudhahar, GA Veltri, N Cristianini; Big Data & Society 2 (1), 1-28, 2015".
Article Type
- Research Highlights

Add a Comment